数据分析的民主化。以Snowflake Cortex开启AI智能体应用的最前沿

围绕数据分析工作过度依赖个人经验、效率不高这一结构性课题,enableX的仓本执行董事讲述了以AI智能体加以解决的愿景。本文解读通过Snowflake Cortex实现数据分析民主化的现实路径。
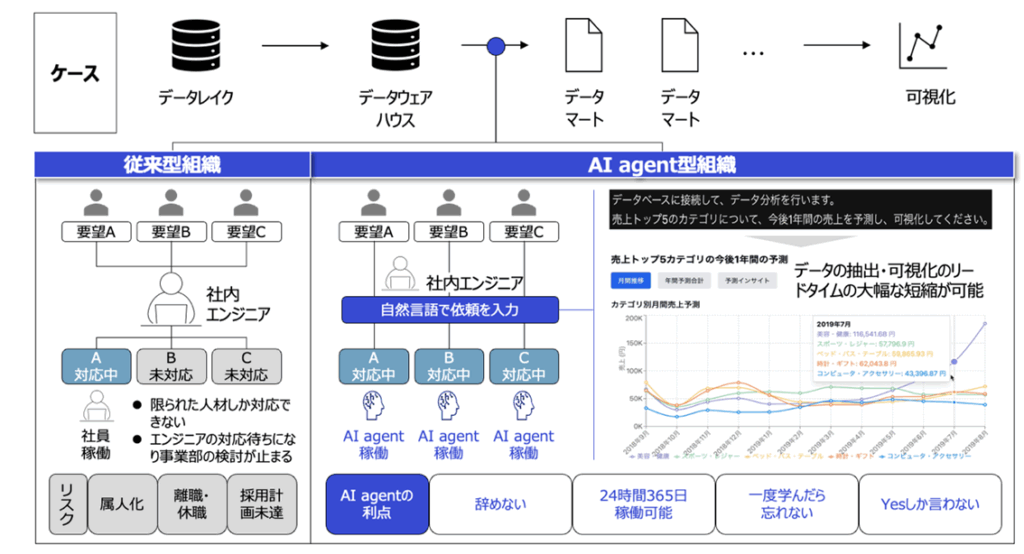
为数据分析工作过度依赖个人经验、效率不高而苦恼的企业不在少数。请求集中于有限的工程师,业务部门的决策因此被拖慢——enableX的仓本岳执行董事讲述了以AI智能体解决这一根本性课题的愿景,以及通往实现路径的思考。

数据分析一线所面临的结构性课题
——当前的数据分析工作存在哪些课题?
仓本:在许多企业,数据分析工作依赖于有限的人才。对内部工程师的请求蜂拥而至,排队等待随之产生;在等待期间,业务部门的讨论也被搁置。这种情况几乎每天都在发生。
更为严重的是人才风险。一旦专家离职或休假,工作便难以正常运转;招聘计划未达成的情况下同样如此。在数据驱动经营被反复强调的当下,这种结构性问题正在严重削弱企业的竞争力。

——也就是说,AI智能体将成为解决方案。
仓本:是的。AI智能体具有人类所不具备的优势——不会离职、可24小时365天持续运转、一旦学会便不会遗忘,并且“只会说Yes”。这听起来像是玩笑,但实际上是一个重要的关键点。
我们所追求的,是仅凭自然语言对AI智能体下达指令,就能完成数据抽取与可视化的环境。例如,输入“销售额前5名品类未来一年的预测”,即可瞬间得到结果。交付周期可由此大幅缩短。
权限管理与治理这道难关
——这听起来非常理想,但在落地实施层面似乎也会面临课题。
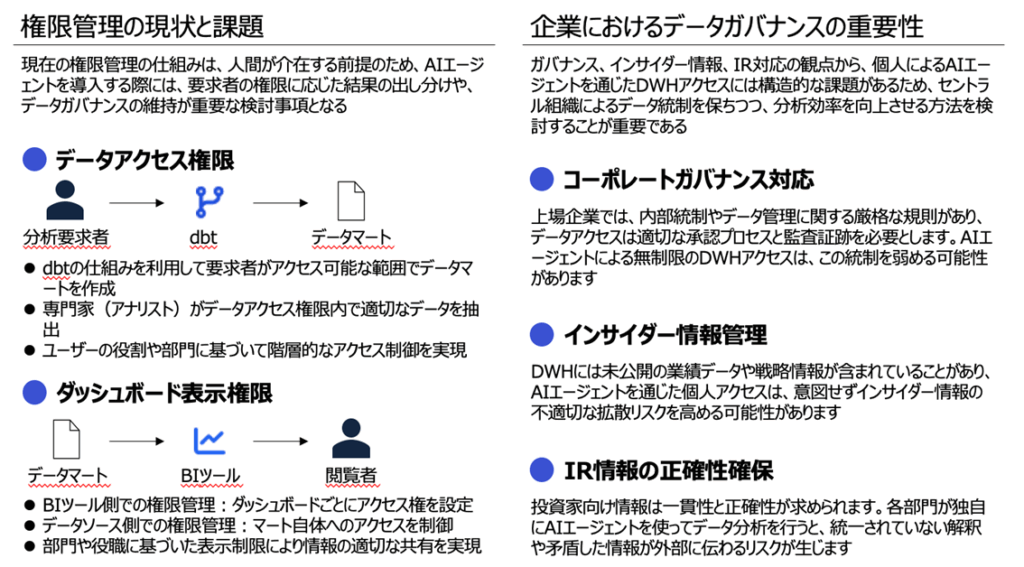
仓本:正是如此。最大的课题在于权限管理与数据治理。现有的权限管理体系是以“有人介入”为前提而设计的。在引入AI智能体时,如何根据请求者的权限对结果加以差异化、并维护数据治理,将成为重要的考量。
尤其是上市公司,从公司治理、内幕信息管理以及IR信息准确性的角度看,个人通过AI智能体访问数据仓库,本身存在结构性课题。
——具体而言,是怎样的课题?
仓本:例如,使用dbt(数据构建工具)的机制时,需要在请求者可访问的范围内构建数据集市。同时,在BI工具一侧与数据源一侧两端都需要进行权限管理。
此外,如果AI智能体可以访问全部数据,就会与各用户的个人权限产生矛盾;但若限制过度,AI的价值又会被削弱。如何化解这一两难,是关键所在。
分阶段方法:从GA4开始的理由
——如何越过这些课题呢?
仓本:我们提倡分阶段的方法,首先从GA4(Google Analytics 4)的数据开始入手。
选择GA4有三个理由。其一,领域专属性较低。作为在全球范围内被广泛使用的标准工具,对特殊专业知识的需求相对较低。其二,方法上的难度较低。基本上以汇总性工作为主,并不要求高级统计或机器学习模型。其三,应用目的清晰。营销举措的效果评估等用途简洁明确。
——也就是说,先从中央组织开始引入。
仓本:是的。与其一开始就全员铺开,不如从中央分析组织开始分阶段引入,以此在维持治理的同时推动效率提升。
关键在于严格地在各用户可访问的数据范围内进行分析。这是AI智能体应用的前提。
容易被忽视的课题——术语定义的统一
——其他还有需要留意的地方吗?
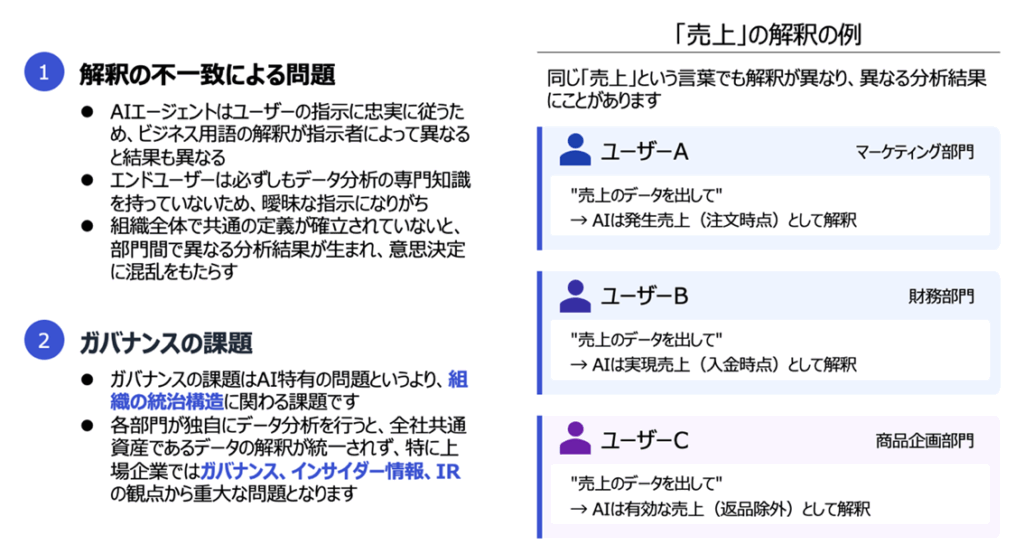
仓本:事实上,AI对术语解读的差异也是一个不容忽视的大课题。同样是“销售额”这一词,营销部门可能解读为“发生销售额(下单时点)”,财务部门解读为“实现销售额(到账时点)”,商品企划部门则解读为“有效销售额(剔除退货)”。
由于AI智能体会忠实于用户的指令,这类解读差异便会直接转化为分析结果的差异。若组织内部未确立共同的定义,各部门便会产出不同的分析结论,从而给决策带来混乱。
——这正是治理层面的本质性课题。
仓本:正是如此。这与其说是AI特有的问题,不如说是涉及组织治理结构的课题。也正因如此,在引入技术的同时,完善数据治理体系才不可或缺。
面向落地的具体路线图
——请介绍一下具体的导入流程。
仓本:我们的提案大体上分为两个阶段。
第一阶段是“AI应用规划”与“基于GA4的演示环境搭建”。首先调研当前的数据环境,设计AI智能体协同的场景;在此基础上,使用GA4数据开展具体的PoC(概念验证)。
——在PoC中具体会做哪些验证?
仓本:例如,我们会验证AI智能体在执行“按品类、按月、同比”等分析时能够多么准确、高效。在可连接BigQuery的情况下,我们会进行接入配置;无法连接时,则从GA4下载数据后进行清洗处理。
关键在于,通过提示工程(prompt engineering)与对GA4事件设计等的同步审视,让AI智能体能够再现以往的GA4报表与典型的分析任务,并通过持续的学习与调优,把准确度提升到可投入实际使用的水平。
Snowflake Cortex——一个现实的选择
——请介绍一下技术上的路径。
仓本:实际上,许多企业在采用MCP(Model Context Protocol)之前,会先从Snowflake Cortex入手。
Snowflake Cortex是Snowflake提供的AI能力,对于数据已存放在Snowflake上的企业而言,是更现实的选择。从安全与治理的角度看,因其能在既有Snowflake环境内闭环完成,落地的门槛也更低。
——与MCP的差异是什么?
仓本:MCP是一种通用协议,能够将各种AI智能体与数据库相连接,但需要重新构建MCP Server。再加上它仍属相对较新的概念,出于安全方面的考量,许多企业在构建上会比较慎重。
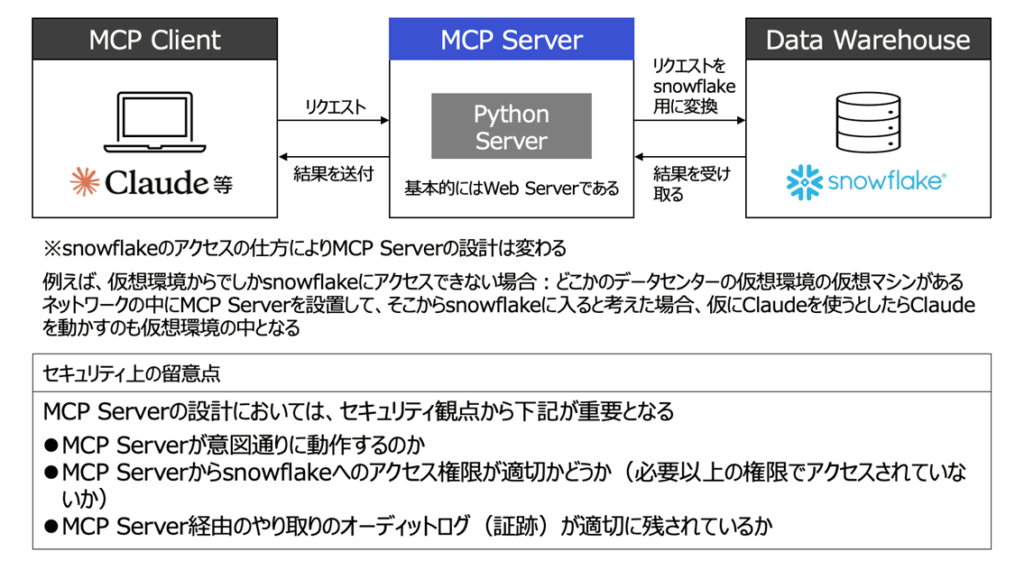
另一方面,Snowflake Cortex已经集成在Snowflake环境内,因而无需额外的基础设施构建。
特别是对以Snowflake为核心的数据基础企业而言,先以Cortex验证AI应用的价值,再根据需要逐步迁移到MCP等更高级机制的方式,是较为现实的路径。
迈向数据分析工作流的革新

——请谈一谈最终所追求的形态。
仓本:我们所追求的是数据分析工作流的革新、开发流程的自动化,以及业务洞察的“去个人化”。
例如,当公司内部的工程师抛出“想要识别雨天销售额上升的商品品类及其原因”这样的命题时,AI智能体能够确定所需的表、设置连接键、进行预处理,并自动生成SQL,甚至完成可视化。
——人类的角色将如何变化呢?
仓本:人类将得以专注于更具创造性、更高价值的工作。从数据收集与加工等作业中被解放出来,把时间投入到洞察的发现与战略的制定上。
关键在于:AI智能体不是人类的替代,而是出色的助手。通过AI与人的协同组队,数据清洗与结构化建模的速度与精度都会得到飞跃性的提升。
——最后,请向读者送上一段寄语。
仓本:数据驱动经营已不再是一个选择,而是一项必要条件。然而现实中,许多企业仍在为数据分析的过度依赖个人与效率低下而苦恼。
从利用Snowflake Cortex等既有基础设施的现实路径切入,再逐步演进到更为先进的机制——我相信,通过这样切实可行的方法,数据分析的民主化是能够实现的。